The function allows to ensemble multiple outlier detection methods to ably compare the outliers flagged by each method.
Usage
multidetect(
data,
var,
select = NULL,
output = "outlier",
exclude = NULL,
multiple,
var_col = NULL,
optpar = list(optdf = NULL, ecoparam = NULL, optspcol = NULL, direction = NULL, maxcol
= NULL, mincol = NULL, maxval = NULL, minval = NULL, checkfishbase = FALSE, mode =
NULL, lat = NULL, lon = NULL, pct = 80, warn = FALSE),
kmpar = list(k = 6, method = "silhouette", mode = "soft"),
ifpar = list(cutoff = 0.5, size = 0.7),
mahalpar = list(mode = "soft"),
jkpar = list(mode = "soft"),
zpar = list(type = "mild", mode = "soft"),
gloshpar = list(k = 3, metric = "manhattan", mode = "soft"),
knnpar = list(metric = "manhattan", mode = "soft"),
lofpar = list(metric = "manhattan", mode = "soft", minPts = 10),
methods,
bootSettings = list(run = FALSE, nb = 5, maxrecords = 30, seed = 1135, th = 0.6),
pc = list(exec = FALSE, npc = 2, q = TRUE, pcvar = "PC1"),
verbose = FALSE,
spname = NULL,
warn = FALSE,
missingness = 0.1,
silence_true_errors = TRUE,
sdm = TRUE,
na.inform = FALSE
)Arguments
- data
dataframe or list. Data sets for multiple or single species after of extraction of environment predictors.- var
character. A variable to check for outliers especially the one with directly affects species distribution such as maximum temperature of the coldest month for bioclimatic variables(IUCN Standards and Petitions Committee, 2022))or stream power index for hydromorphological parameters(Logez et al., 2012). This parameter is necessary for the univariate outlier detection methods such as Z-score.- select
vectorThe columns that will be used in outlier detection. Make sure only numeric columns are accepted.- output
character. Eitherclean: for a data set with no outliers, oroutlier: to output a dataframe with outliers. Defaultoutlier.- exclude
vector. Exclude variables that should not be considered in the fitting the one class model, for examplexandycolumns or latitude/longitude or any column that the user doesn't want to consider.- multiple
logical. If the multiple species are considered, then multiple must be set toTRUEandFALSEfor single species.- var_col
string. A column with species names ifdatasetfor species is a dataframe not a list. Seepred_extractfor extracting environmental data.- optpar
list. Parameters for species optimal ranges like temperatures ranges. For details checkecological_ranges.- kmpar
list. Parameters for k-means clustering like method and number of clusters for tuning. For details, checkxkmeans.- ifpar
list. Isolation forest parameter settings. Parameters of the isolation model that are required include the cutoff to be used for denoting outliers. It ranges from0 to 1but Default0.5. Also, the size of data partitioning for training should be determined. For more details check(Liu et al. 2008)- mahalpar
list. Parameters for Malahanobis distance which includes varying the mode of outputmahal.- jkpar
list. Parameters for reverse jackknifing mainly the mode used. For detailsjknife.- zpar
list. Parameters for z-score such asmodeandxparameter. For detailszscore- gloshpar
list. Parameters for global local outlier score from hierarchies such as distance metric used. For detailsxglosh.- knnpar
list. Parameters for varying the distance matrix such asEuclideanorManhattan distance. For detailsxknn- lofpar
list. Parameters for local outlier factor such as the distance matrix and mode of method implementation such as robust and soft mode. For detailsxlof.- methods
vector. Outlier detection methods considered. UseextractMethodsto get outlier detection methods implemented in this package.- bootSettings
list. A list of parameters to implement bootstrapping mostly for records below 30. For details checksboots.- pc
list. A list of parameters to implement principal component analysis for dimesnion reduction. For details checkspca.- verbose
logical. whether to return messages or not. DefaultFALSE.- spname
string. species name being handled.- warn
logical. Whether to return warning or not. DefaultTRUE.- missingness
numeric. Allowed missing values in a column to allow a user decide whether to remove the individual columns or rows from the data sets. Default 0.1. Therefore, if a column has more than 10% missing values, then it will be removed from the dataset rather than the rows.- silence_true_errors
logical. Show execution errors and therefore for multiple species the code will break if one of the methods fails to execute.- sdm
logical If the user sets
TRUE, strict data checks will be done including removing all non-numeric columns from the datasets before identification of outliers. If set toFALSEnon numeric columns will be left in the data but the variable of concern will checked if its numeric. Also, only univariate methods are allowed. Checkbroad_classifyfor the broad categories of the methods allowed.- na.inform
logicalInform on the NAs removed in executing general datasets. DefaultFALSE.
Value
A list of outliers or clean dataset of datacleaner class. The different attributes are
associated with the datacleaner class from multidetect function.
result:dataframe. list of dataframes with the outliers flagged by each method.mode:logical. Indicating whether it was multiple TRUE or FALSE.varused:character. Indicating the variable used for the univariate outlier detection methods.out:character. Whether outliers where indicated by the user or no outlier data.methodsused:vector. The different methods used the outlier detection process.dfname:character. The dataset name for the species records.exclude:vector. The columns which were excluded during outlier detection, if any.
Details
This function computes different outlier detection methods including univariate, multivariate and species
ecological ranges to enables seamless comparison and similarities in the outliers detected by each
method. This can be done for multiple species or a single species in a dataframe or lists or dataframes
and thereafter the outliers can be extracted using the extract_clean_data function.
References
IUCN Standards and Petitions Committee. (2022). THE IUCN RED LIST OF THREATENED SPECIESTM Guidelines for Using the IUCN Red List Categories and Criteria Prepared by the Standards and Petitions Committee of the IUCN Species Survival Commission. https://www.iucnredlist.org/documents/RedListGuidelines.pdf.
Liu, F. T., Ting, K. M., & Zhou, Z. H. (2008, December). Isolation forest. In 2008 eighth ieee international conference on data mining (pp. 413-422). IEEE.
Examples
# \donttest{
#' #====
#1. Mult detect for general data analysis using iris data
#===
# the outliers are introduced for testing purposes
irisdata1 <- iris
#introduce outlier data and NAs
rowsOutNA1 <- data.frame(x= c(344, NA,NA, NA),
x2 = c(34, 45, 544, NA),
x3= c(584, 5, 554, NA),
x4 = c(575, 4554,474, NA),
x5 =c('setosa', 'setosa', 'setosa', "setosa"))
colnames(rowsOutNA1) <- colnames(irisdata1)
dfinal <- rbind(irisdata1, rowsOutNA1)
#===========
setosadf <- dfinal[dfinal$Species%in%"setosa",c("Sepal.Width", 'Species')]
setosa_outlier_detection <- multidetect(data = setosadf,
var = 'Sepal.Width',
multiple = FALSE, #'one species
methods = c("adjbox", "iqr", "hampel","jknife",
"seqfences", "mixediqr",
"distboxplot", "semiqr",
"zscore", "logboxplot", "medianrule"),
silence_true_errors = FALSE,
missingness = 0.1,
sdm = FALSE,
na.inform = TRUE)
#> 1 (1.85%) NAs removed for parameter Sepal.Width.
#======
#2.all species
#=====
multspp_outlier_detection <- multidetect(data = dfinal,
var = 'Sepal.Width',
multiple = TRUE, #'for multiple species or groups
var_col = "Species",
methods = c("adjbox", "iqr", "hampel","jknife",
"seqfences", "mixediqr",
"distboxplot", "semiqr",
"zscore", "logboxplot", "medianrule"),
silence_true_errors = FALSE,
missingness = 0.1,
sdm = FALSE,
na.inform = TRUE)
#> 1 (1.85%) NAs removed for parameter Sepal.Width.
#> 0 (0%) NAs removed for parameter Sepal.Width.
#> 0 (0%) NAs removed for parameter Sepal.Width.
ggoutliers(multspp_outlier_detection)
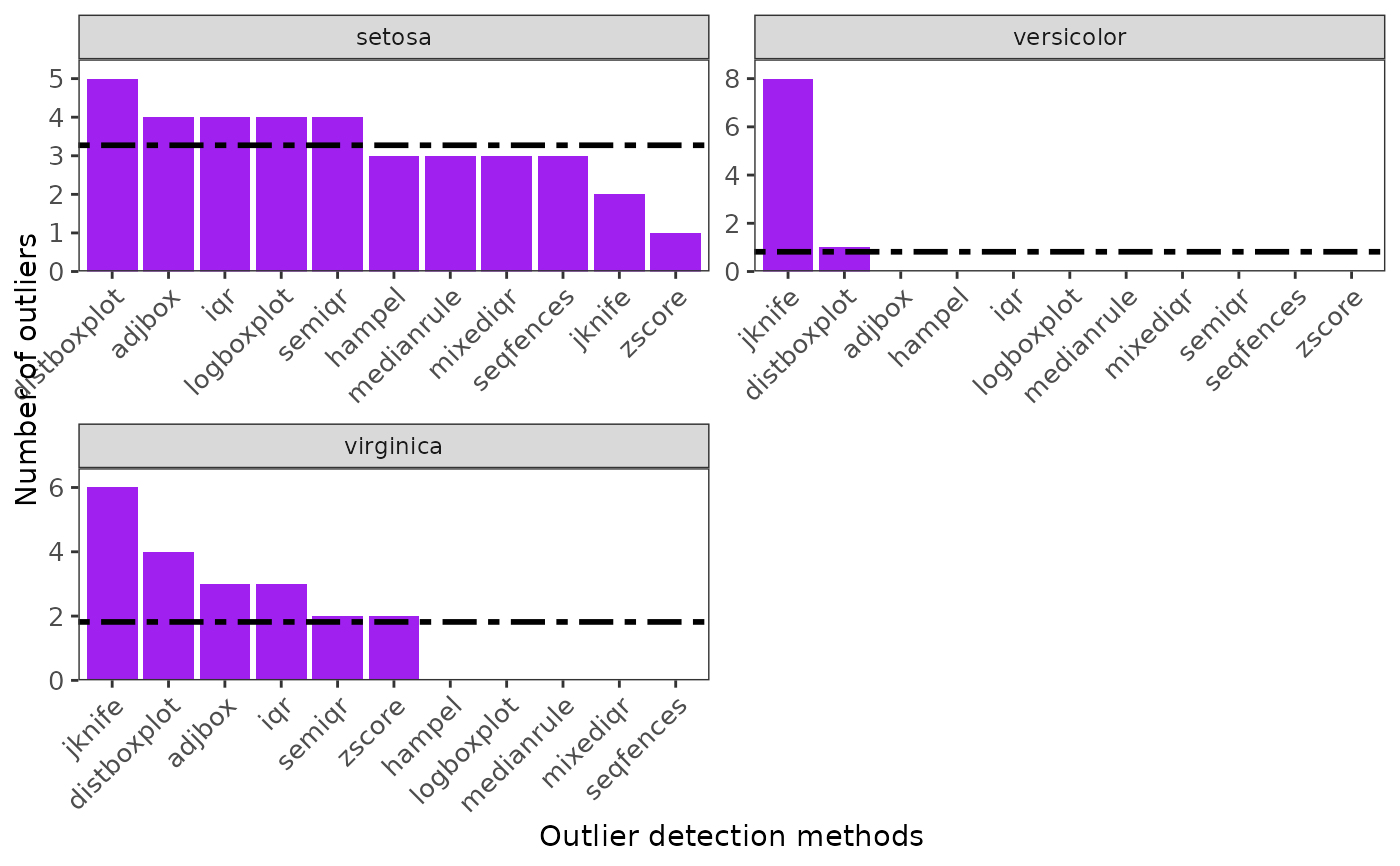 #======
#3. Multidetect for environmental data
#======
#'Species data
data("abdata")
#area of interest
danube <- system.file('extdata/danube.shp.zip', package='specleanr')
db <- sf::st_read(danube, quiet=TRUE)
worldclim <- terra::rast(system.file('extdata/worldclim.tiff', package='specleanr'))
abpred <- pred_extract(data = abdata,
raster= worldclim ,
lat = 'decimalLatitude',
lon= 'decimalLongitude',
colsp = 'species',
bbox = db,
minpts = 10,
list=TRUE,
merge=FALSE)
about_df <- multidetect(data = abpred, multiple = FALSE,
var = 'bio6',
output = 'outlier',
exclude = c('x','y'),
methods = c('zscore', 'adjbox','iqr', 'semiqr','hampel', 'kmeans',
'logboxplot', 'lof','iforest', 'mahal', 'seqfences'))
ggoutliers(about_df)
#======
#3. Multidetect for environmental data
#======
#'Species data
data("abdata")
#area of interest
danube <- system.file('extdata/danube.shp.zip', package='specleanr')
db <- sf::st_read(danube, quiet=TRUE)
worldclim <- terra::rast(system.file('extdata/worldclim.tiff', package='specleanr'))
abpred <- pred_extract(data = abdata,
raster= worldclim ,
lat = 'decimalLatitude',
lon= 'decimalLongitude',
colsp = 'species',
bbox = db,
minpts = 10,
list=TRUE,
merge=FALSE)
about_df <- multidetect(data = abpred, multiple = FALSE,
var = 'bio6',
output = 'outlier',
exclude = c('x','y'),
methods = c('zscore', 'adjbox','iqr', 'semiqr','hampel', 'kmeans',
'logboxplot', 'lof','iforest', 'mahal', 'seqfences'))
ggoutliers(about_df)
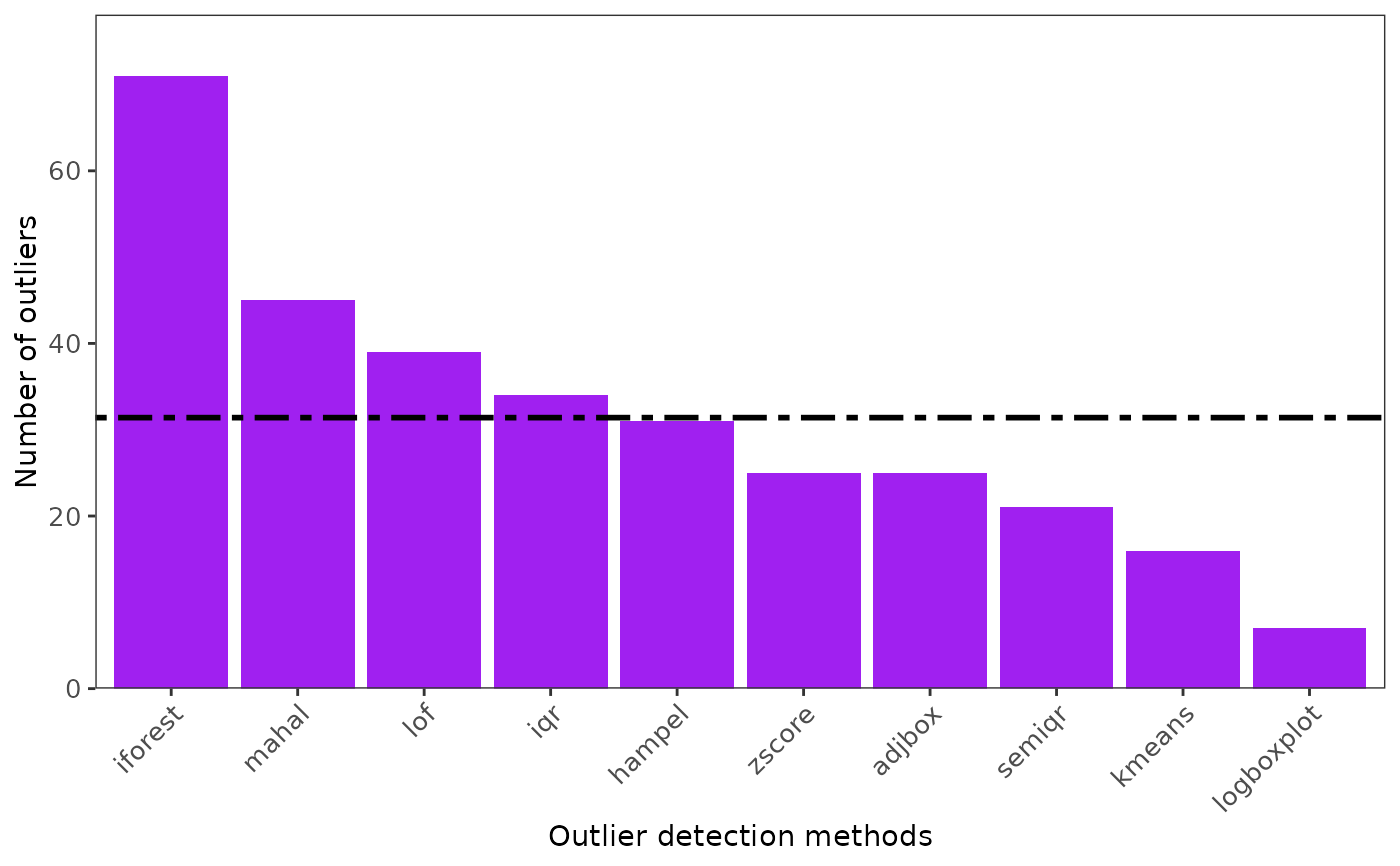 #==========
#4. For mulitple species in species distribution models
#======
data("efidata")
data("jdsdata")
matchdata <- match_datasets(datasets = list(jds = jdsdata, efi=efidata),
lats = 'lat',
lons = 'lon',
species = c('speciesname','scientificName'),
date = c('Date', 'sampling_date'),
country = c('JDS4_site_ID'))
#extract data
rdata <- pred_extract(data = matchdata,
raster= worldclim ,
lat = 'decimalLatitude',
lon= 'decimalLongitude',
colsp = 'species',
bbox = db,
minpts = 10,
list=TRUE,
merge=FALSE)
#optimal ranges in the multidetect: made up
multspout_df <- multidetect(data = rdata, multiple = TRUE,
var = 'bio6',
output = 'outlier',
exclude = c('x','y'),
methods = c('zscore', 'adjbox','iqr', 'semiqr','hampel', 'kmeans',
'logboxplot', 'lof','iforest', 'mahal', 'seqfences'))
ggoutliers(multspout_df, "Anguilla anguilla")
#==========
#4. For mulitple species in species distribution models
#======
data("efidata")
data("jdsdata")
matchdata <- match_datasets(datasets = list(jds = jdsdata, efi=efidata),
lats = 'lat',
lons = 'lon',
species = c('speciesname','scientificName'),
date = c('Date', 'sampling_date'),
country = c('JDS4_site_ID'))
#extract data
rdata <- pred_extract(data = matchdata,
raster= worldclim ,
lat = 'decimalLatitude',
lon= 'decimalLongitude',
colsp = 'species',
bbox = db,
minpts = 10,
list=TRUE,
merge=FALSE)
#optimal ranges in the multidetect: made up
multspout_df <- multidetect(data = rdata, multiple = TRUE,
var = 'bio6',
output = 'outlier',
exclude = c('x','y'),
methods = c('zscore', 'adjbox','iqr', 'semiqr','hampel', 'kmeans',
'logboxplot', 'lof','iforest', 'mahal', 'seqfences'))
ggoutliers(multspout_df, "Anguilla anguilla")
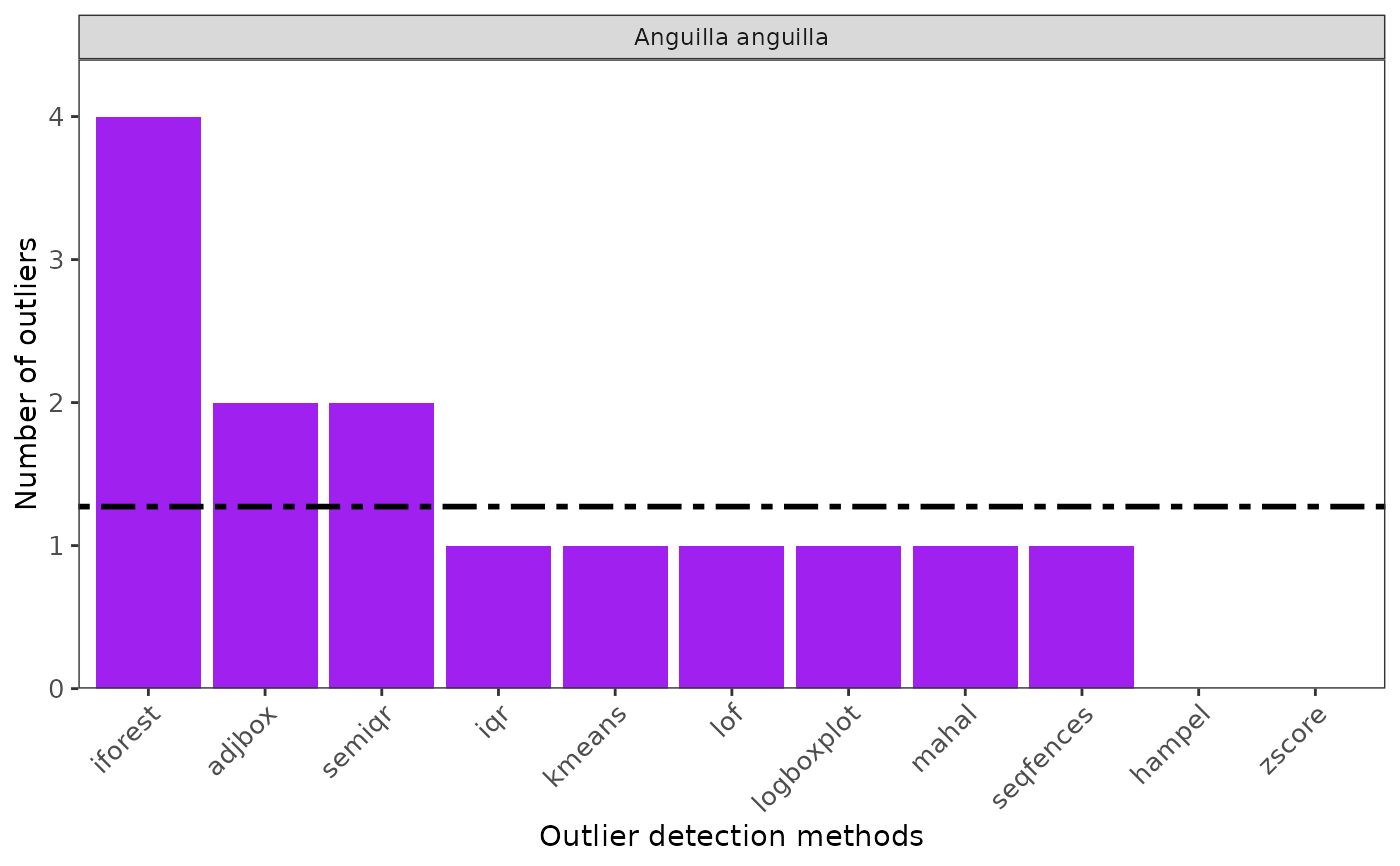 #====================================
#5. use optimal ranges as a method
#create species ranges
#===================================
#max temperature of "Thymallus thymallus" is made up to make it appear in outliers
optdata <- data.frame(species= c("Phoxinus phoxinus", "Thymallus thymallus"),
mintemp = c(6, 1.6),maxtemp = c(20, 8.6),
meantemp = c(8.69, 8.4), #'ecoparam
direction = c('greater', 'greater'))
ttdata <- rdata["Thymallus thymallus"]
#even if one species, please indicate multiple to TRUE, since its picked from pred_extract function
thymallus_out_ranges <- multidetect(data = ttdata, multiple = TRUE,
var = 'bio1',
output = 'outlier',
exclude = c('x','y'),
methods = c('zscore', 'adjbox','iqr', 'semiqr','hampel', 'kmeans',
'logboxplot', 'lof','iforest', 'mahal', 'seqfences', 'optimal'),
optpar = list(optdf=optdata, optspcol = 'species',
mincol = "mintemp", maxcol = "maxtemp"))
ggoutliers(thymallus_out_ranges)
#====================================
#5. use optimal ranges as a method
#create species ranges
#===================================
#max temperature of "Thymallus thymallus" is made up to make it appear in outliers
optdata <- data.frame(species= c("Phoxinus phoxinus", "Thymallus thymallus"),
mintemp = c(6, 1.6),maxtemp = c(20, 8.6),
meantemp = c(8.69, 8.4), #'ecoparam
direction = c('greater', 'greater'))
ttdata <- rdata["Thymallus thymallus"]
#even if one species, please indicate multiple to TRUE, since its picked from pred_extract function
thymallus_out_ranges <- multidetect(data = ttdata, multiple = TRUE,
var = 'bio1',
output = 'outlier',
exclude = c('x','y'),
methods = c('zscore', 'adjbox','iqr', 'semiqr','hampel', 'kmeans',
'logboxplot', 'lof','iforest', 'mahal', 'seqfences', 'optimal'),
optpar = list(optdf=optdata, optspcol = 'species',
mincol = "mintemp", maxcol = "maxtemp"))
ggoutliers(thymallus_out_ranges)
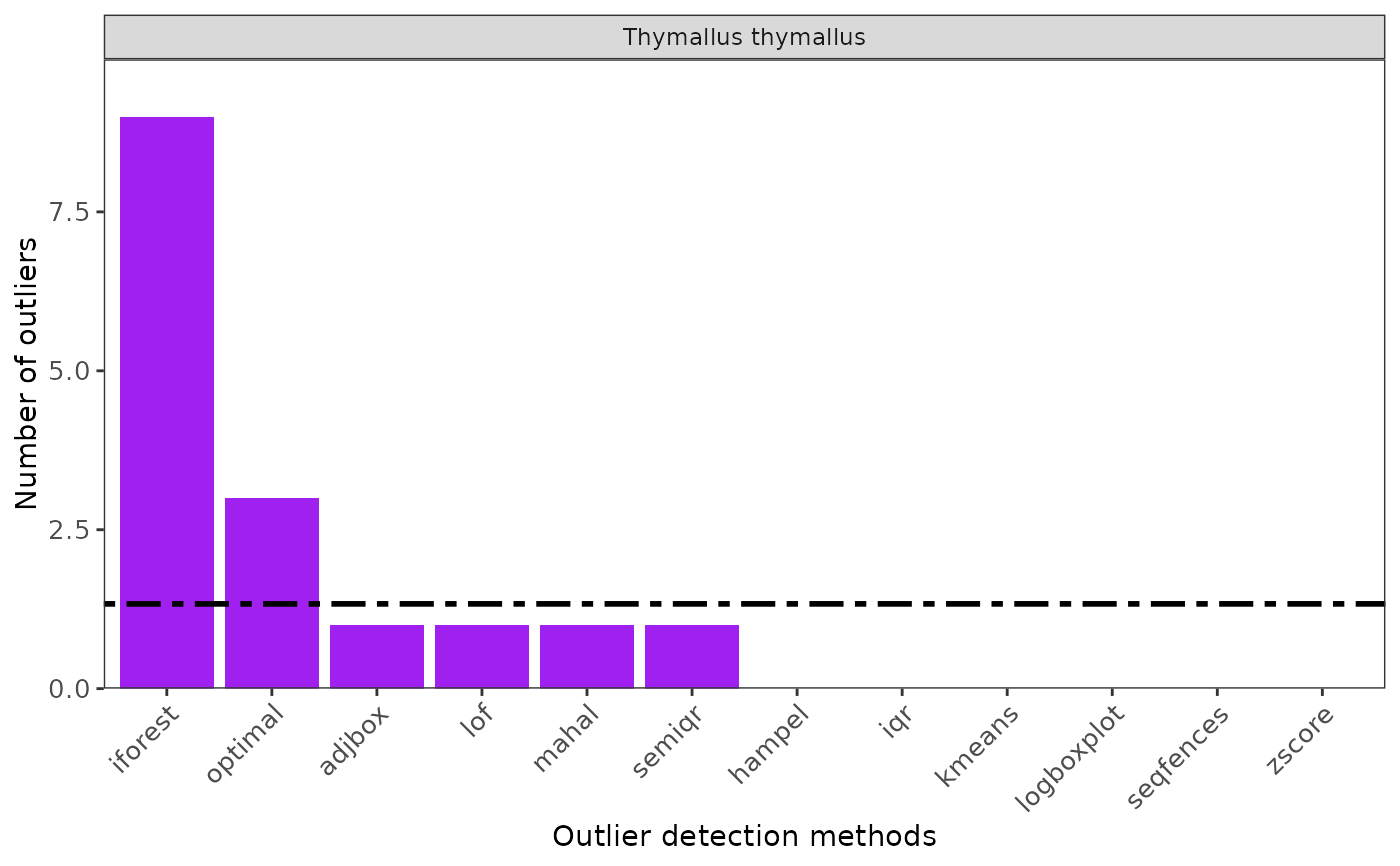 # }
# }